The Imperial College study, “Impact of non-pharmaceutical interventions (NPIs) to reduce COVID19 mortality and healthcare demand,” from the Imperial College COVID-19 Response team, is said to have influenced both the United Kingdom and the United States governments.
It models how the SARS-CoV-2 virus and its resulting disease, COVID-19, might spread through those two countries. The numbers of cases of COVID-19 and resulting deaths are high, as are the amounts of time predicted necessary for social distancing. It looks at interventions that can bring the numbers down or spread them out in time.
All models are wrong, but some are useful, it is said. It can be misleading to simply take those bottom-line numbers, though. What models are good for is looking at what changes can be put into the system and which are most important.
This is going to be somewhat wonky, so I’ll interpolate, in italics, tl;drs that will summarize the following material.
tl;dr: This is a description of the model. If you don’t read anything else in this section, read this and look at the demonstrations. They are how the model works, but it applies different numbers to the probabilities that a red dot will turn a blue dot red.
The model used is an individual-based simulation model. That means that it follows simulated individuals through time as they participate in communities within the household, at school, in the workplace and in the wider community. It then combines the histories of many individuals to give an overall outcome.
Calculating these interactions requires:
- Age and household distribution size – from census data
- Population of schools distributed proportional to local population density – from data on average class sizes and staff-student ratios
- Size and geographical location of workplace.
These data are generally available and reasonably reliable.
The virus is transmitted through contacts between susceptible and infectious individuals in those four places. Transmission in the community depends on spatial distance between contacts, and contacts in schools are taken to be double those elsewhere.
From these calculations, the paper concludes that “approximately one third of transmission occurs in the household, one third in schools and workplaces and the remaining third in the community. These contact patterns reproduce those reported in social mixing surveys.”
That’s the groundwork for the rest of the analysis. Now come the numbers we don’t know well at all. A model like this is made up of equations that represent how likely it is that an interaction between a susceptible and an infectious individual will transmit the disease. Initially, with a new virus like this, everyone is susceptible. When a person is infected, they are no longer susceptible. Likewise, they may remain immune to the virus after they recover. We don’t know that this is the case for SARS-CoV-2, but there are some indications it may be, and that is the assumption in the model.
Because the virus is new, none of these numbers is well known. Sources are given in parentheses. If no source is listed, it is assumed by the authors.
- Incubation period 5.1 days (from references)
- Infectiousness from 12 hours prior to the onset of symptoms for those that are symptomatic and from 4.6 days after infection in those that are asymptomatic with an infectiousness profile over time that results in a 6.5-day mean generation time (no reference given)
- R0 = 2.4 but values between 2.0 and 2.6 were examined. R0 is the number of other people infected by one infectious person. (Based on fits to the early growth-rate of the epidemic in Wuhan)
- Symptomatic individuals are 50% more infectious than asymptomatic individuals (no reference given)
- Infectiousness is assumed to be variable, described by a gamma distribution with mean 1 and shape parameter α = 0.25
- On recovery from infection, individuals are assumed to be immune to re-infection in the short term. (analogy to seasonal influenza)
- Start date: early January 2020
- Doubling time: 5 days
- Rate of seeding calibrated to give local epidemics which reproduced the observed cumulative number of deaths in GB or the US seen by 14th March 2020.
- two-thirds of cases are sufficiently symptomatic to self-isolate (if required by policy) within 1 day of symptom onset
- mean delay from onset of symptoms to hospitalization of 5 days
- The age-stratified proportion of infections that require hospitalisation and the infection fatality ratio (IFR) were obtained from an analysis of a subset of cases from China. These estimates were corrected for non-uniform attack rates by age and when applied to the GB population result in an IFR of 0.9% with 4.4% of infections hospitalized
- 30% of those that are hospitalized will require critical care (invasive mechanical ventilation or ECMO) (based on early reports from COVID-19 cases in the UK, China, and Italy)
- 50% of those in critical care will die and an age-dependent proportion of those that do not require critical care die (expert clinical opinion)
- Bed demand numbers based on a total duration of stay in hospital of 8 days if critical care is not required and 16 days (with 10 days in ICU) if critical care is required. With 30% of hospitalised cases requiring critical care, the overall mean duration of hospitalization is 10.4 days. (consistent with general pneumonia admissions)
All these numbers look similar to numbers I’ve seen tumbling out in scientific papers and other places. None look wildly off. But there are reservations about some that I’ll discuss later.
Put those numbers into the model, and you can calculate numbers of hospital beds needed, deaths over time, when the worst of the epidemic will come, when it will die down, and other numbers we’ve all had questions about. This is the case without intervention. These are the worst numbers you will see in media reports of this study.
To get a feel for how the model works, look at this wonderful visualization by Harry Stevens at Washington Post. The Imperial College model sets probabilities that a red dot will collide with a blue dot and turn it red. It also sets up four different areas – household, school, workplace and the wider community – as the second Washington Post simulation has two. The Washington Post simulation is much simpler than the Imperial College model, but it shows how it works.
Intervention Scenarios
tl;dr: Five interventions involving various degrees of social distancing show improvements over the base case. The best case is to combine them all.
The conditions can be varied and the calculations repeated for different scenarios. The paper calls them non-pharmaceutical interventions because they don’t involve treatment drugs or vaccines, but rather behavior modifications.
Five interventions were studied:
- Case isolation – People with symptoms isolate themselves at home and reduce interaction with family members
- Voluntary home quarantine – People with symptoms remain at home but do not isolate themselves from family members, who remain at home
- Social distancing of those over 70 years – Reduce contact outside the home, but contact within the home increases
- Social distancing of the entire population – Same as the previous, but school contact rates remain the same
- Closure of schools and universities – Closure of all schools and 75% of universities. Contact increases at home and in the community.
Policies are assumed to be in force for 3 months in four scenarios, 4 months for social distancing of those over 70.
The authors say that their assumptions for the scenarios are pessimistic with regard to the changes in contacts, which seems to mean that actual mitigation by these interventions may be better than the results given in the paper.
Results
tl;dr: The epidemic will peak this summer, with or without intervention. There may be a secondary peak later. Things may not stabilize until a vaccine is available.
This is the base case, with no interventions: a half million dead in the UK and over 2 million dead in the US, peaking in late June and July, tailing off to August.
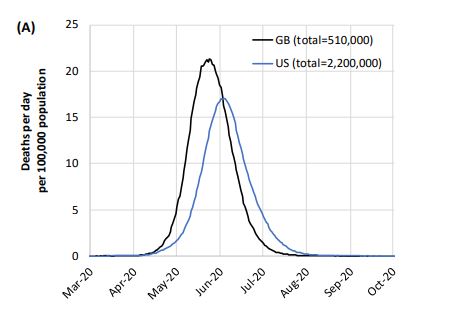
Critical care bed capacity could be exceeded as early as the second week in April. Simulations were also run for the individual American states, with broadly similar results. The graph is hard to read, but you can find it in the paper.
The aim of the interventions is to flatten the curve. That also means that they will increase the duration and make the peak later.
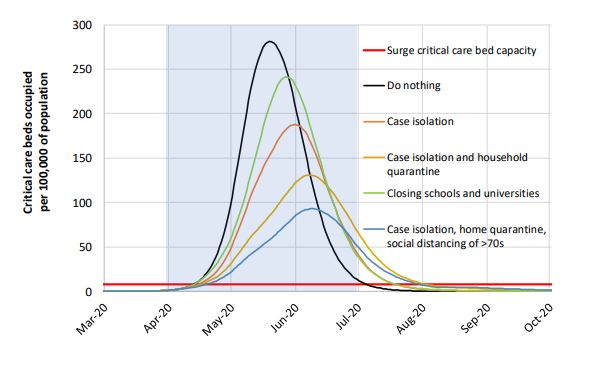
Obviously, all of the interventions are needed. This is probably the most significant finding of the study, and one that should hold up despite any reservations I’ll express later.
The paper goes into more complex strategies as well. If infections go down and controls are released, there is likely to be a second, smaller peak in the fall. Some controls may continue to be necessary until a vaccine is available.
Take-Aways
- The shapes of the curves are probably more reliable than absolute numbers or dates. Interventions are important in lessening the effect of the virus.
- It’s going to be a difficult twelve to eighteen months. After the biggest danger period from the virus is past, we are going to have to pick up the pieces of the economy.
- ALL of the interventions are necessary to flatten the curve and save lives.
Some thoughts on the model and its parameters:
The model should be reliable. It’s been used before, and models of this type are much less complex than, say, climate models. Some of the parameters, like those derived from the Chinese experience, may be pessimistic, but others may not. Overall, the choices of parameters seem to be reasonable, given the newness of the virus and thus the lack of information on its behavior.
The experiences in Wuhan and Italy have been particularly virulent, so basing parameters on them may give a pessimistic result. It would be useful to get comparable numbers from Singapore and South Korea. Unfortunately, the United States seems to be on a trajectory more like Italy’s. For doubling time, the model uses 5.1 days, but data I see looks like the doubling time in the United States is 3 days; others say 1.9 days. That’s going to make everything happen faster. The lower number could be because of increased testing, but I’m not convinced of that.
Although indications are that people who recover have some immediate immunity to reinfection, this is not well known. There is still no test for antibodies, although several laboratories are working on one. Immunity makes a big difference in whether there will be a second wave and how big it will be.
I would like to see a sensitivity analysis of the model. That would show which parameters are most important and how much uncertainty in them affects the results. To some degree, the calculations of the interventions are an implicit sensitivity analysis, and the paper has a few comments about parameter sensitivities. Seems to be nothing surprising, with no particular intervention more effective than others. No silver bullet.
The biggest uncertainty is not having testing data. We need those tests for many reasons. We need tests to monitor whether seemingly well people are carrying the virus so that they can isolate themselves. We need tests so that people in early stages of the illness can be treated if a treatment becomes available. We need tests to see if people become immune to the virus, and then we need to test people so that they can go back to work if they are immune. More in a Twitter thread.
We will need patience. We will not see results from actions we take now for weeks. Things will get worse no matter what we do, but they will be less worse if we do these interventions conscientiously. Authorities in the states have the right idea and are taking action. We will see things start to improve in the summer.
Addendum: Columbia University has done a modeling study that shows results that are similar qualitatively and has the same takeaways I’ve given here. The big difference is in the numbers. The New York Times gives the results of that study, but it’s not possible from what is in that article to say what the differences are between the two. Hopefully Columbia will publish the study.
Because people who don’t know me are likely to read this post: I’m a chemist who has worked with modelers of chemical reactions. The mathematics of an epidemic are very similar to the mathematics of chemical reaction kinetics. I’ve developed the basis for chemical models and understand how models are put together and used. I’ve managed a project in which chemical models were used to get practical results. Check me out on Google Scholar to see some of my papers.
Cross-posted to Nuclear Diner

JPL
Horrifying.
MattF
Here, via Terry Tao, is a video lecture from Nicholas Jewell (a recognized expert in the field):
https://www.youtube.com/watch?v=MZ957qhzcjI
See Tao’s blog for background info.
MomSense
Here’s a weird question. What if we’re too successful at social distancing and we don’t have sufficient herd immunity?
schrodingers_cat
Has anyone come across modeling of historical epidemics/pandemics like the Spanish Flu? Thanks.
Betty
Very informative post, Cheryl.
JPL
@MomSense: We better because as soon as we pass through this, I’m going to spend lots of time hugging my little grandson.
Cheryl Rofer
@MomSense: That’s what will give a second peak in the fall.
zhena gogolia
If I don’t die of the virus, I’ll have starved to death by then.
zzyzx
My biggest fear is page 10. It’s that we do everything, lock everything down, destroy the economy, and all we get out of it is that everything happens in the fall instead of the spring. “Fortunately” I think things will be bad enough right now because we waited too long, that we have a decent shot at having two smaller curves instead of one big one.
There is no good answer to this. None.
zzyzx
@MomSense:
that’s what I mentioned below your post, right above this. It’s why I’m thinking of this as lowering contact, not eliminating.
rikyrah
Nicole
Terrifying. But it’s less scary to know than to not know. Thanks for this.
As a child, I loved reading my parents’ copies of The People’s Almanac, especially the section on natural and man-made disasters. The Spanish Influenza was one of the entries, and although I haven’t read it in decades, I seem to recall it ending with some frightening what if scenario, and like, what if something like this happens again. We’re about to find out. Not in the same way, of course, science has advanced, and we know what causes this, but in terms of the fear and the isolation. We’re getting a repeat a century later.
snoey
@rikyrah: All common contact points – don’t waste gloves – carry sanitizer in your car and wash your hands afterwards.
My daughter the ID doctor helped put this together:
https://covid-101.org
Kirk Spencer
The thing I keep seeing unmodeled for the us is the nature of it’s it’s and non-homogeneous responses. I’m thinking Europe, not any particular nation in Europe, would be a better baseline.
Alternately a model that regionalized the US based on responses and interregional traffic patterns. Yes I cnow that’s recursive but I think you all get what I meant.
Simple example. I think Texas is about a week behind California on the curve. Gut feels ng, haven’t run need mbers. But since Texas won’t shut down like California I expect the end curve to be steeper.
Punchy
And what becomes of the growing number of anti-vaxxers when they refuse to get this vaccine? My hope is that they’re shunned from schools, sports, and birthday parties. Their parents are fined $1000s of dollars per year and lose their jobs (what employer wants this shit to affect them again?)
My guess is that they’ll just scream “religion, bitches!” and half of America will nod in agreement that, yeah, good enough excuse. And we’ll see flare-ups every other month…..
Cheryl Rofer
@Kirk Spencer: The Imperial College group modeled all the individual states, as did the Columbia University study. There are some differences, but not big ones, among the states.
E.
Good God. If this lasts eighteen months there won’t be a single small business left in America. Certainly not mine! What is this country going to look like when this is over?? A: Very different. Probably worse. I wonder if there is a way to steer it toward looking better? How many of the survivors are going to lose their jobs and then their homes? I likely will, assuming I survive the virus. Trying not to spin out of control here but the anxiety and precariousness of my position (and many many many others) is nearly overwhelming. Why do we have to have such a terrible government right now. Ugh.
KnowLittle
I like Dave Lee’s suggested approaches – try to avoid economic suicide:
https://www.youtube.com/watch?v=HJPRKw14Fys
jlowe
A medical data analytics firm has released a tool based on the SIR model to aid hospital administrators and health services decision makers in evaluating the impact of CoVID-19 on ICU bed and ventilator capacity. Likely a down-scaled version of the Imperial College model for local and regional conditions though I’m still getting the feel of it. http://predictivehealthcare.pennmedicine.org/2020/03/14/accouncing-chime.html. As with any model, interpret the output with a spirit of caution. I’m looking at it as a learning tool for risk communication.
O. Felix Culpa
Excellent post, Cheryl. Thank you.
@snoey: Thanks also for the link and to your daughter for contributing to the website.
Cheryl Rofer
@E.: After the peak in the summer, what is likely to happen is that restrictions will be removed, one or a few at a time, there will be some rebound, maybe some restrictions will be reinstated.
This is why Congress needs to stop messing around and pass financial stimulus NOW. It doesn’t have to be perfect – we can fix the details later.
MartinNM
I wonder about the effect that a lack of resources would have on these numbers. I see that 30% will need critical care, and 50% of those in critical care will die, but it seems there might be a gap between those who need critical care and those that receive it. Any difference may or may not be due to resource shortages, but that would certainly be one cause of such an effect. Another effect that would be interesting to model would be the impact of resource “displacement” (my term), or the effect of using limited resources to treat C19 patients that would otherwise have been used for other (critical) purposes.
debbie
This has nothing to do with modeling, but I just listened to an interview with an Irani foreign policy expert who pointed out that because sanctions were still in place, Iran couldn’t get the supplies they needed to fight COVID-19. Trump needs to at least temporarily lift sanctions ASAP.
rikyrah
Fair Economist
I was going to say – “really good presentation of the paper” until I got to the end.
YOU STOPPED BEFORE GETTING TO THE MAIN POINT.
The point of the paper is that any mitigation strategy is unacceptable and we *must* pursue a suppression strategy by combining these approaches. Possible combinations are discussed in the text, and a graph is provided in Figure 3 on page 10.
Trevor Bedford has pointed out they didn’t analyze test/trace as an auxiliary technique for suppression, which could substantially reduce how onerous a suppression regime will be.
(A number of Twitter analyses had the same flaw.)
Fair Economist
@rikyrah: Powell is competent, but it’s a real harm than Trump fired Yellen, who is an unusually insightful and resourceful economist. We’d be much better off were she running the money show. The image of somebody of her caliber running sims on cast-off computers in her apartment while supporting her son is depressing, like something out of Dickens.
Sandia Blanca
@snoey: great resource, thank you for sharing it.
Cermet
First, it is highly unlikely that any infected person – once they recover – isn’t immue to this strain. The fear is if it mutates – then, the issue is how sick does said immue person become if they get it again; likely, a good bit less but that still means deaths. Second, the economic impact isn’t modeled – just assumed by us readers to be really bad (I certainly would believe that) but this depends on the length (not height of the curve) of the infection wave.
If the curve is flatten than the death rate is far over estimated (a good thing) but the economic damage, of course, is far greater.
This tRump virus would never have gotten as bad if the average rethug voter weasn’t determined to own the libs. We suffer social and economic disaster because these racist voters decided to prove that stupid can run this country.
Fair Economist
@MomSense: We will never get herd immunity by this via exposure. Too many deaths. Socially protective immunity will require vaccines.
If there is a second go-around in the fall, we will at least have immune healthcare workers, which will be great for the hospitals.
debbie
@Fair Economist:
I think she would also have been better at standing up to Trump.
LarryB
It is my understanding that herd immunity, either through infection/recovery or (a currently unavailable) vaccination, is the only way these infection curves ever go back to zero. The only question is how long that will be and how many will die along the way due to inadequate/unavailable medical support.
Fair Economist
@Cermet: Research on common cold coronaviruses shows that immunity fades over time and it’s possible to catch it again after 1 to a few years. Repeat infection will probably be milder, though. Mutation will eventually generate strains different enough to evade your immune response, but it’s a slower process and probably not relevant. The kind of interspecies chromosome swapping influenza does to generate radically new strains is impossible with coronaviruses.
Kirk Spencer
@Cheryl Rofer: thank you. I’ll read them when I get home to a computer instead of trying to read them on the small screen.
MomSense
@rikyrah:
I’m doing the same except leaving food and drinks outside my oldest son’s bedroom door. He came home on Monday because his roommates were still working in restaurants and going out.
Cheryl Rofer
@Fair Economist: Compare
with
I hate, hate, hate the “mitigation” and “suppression” terminology. I have to look every time I see those words to figure out what they mean, and even now I’m not sure. I think “mitigation” means one of the interventions and “suppression” means all of them, but, as I say, I’m not sure.
MomSense
Since this thread is dedicated to this pandemic, I’ll put another grim thought here. I bet that motherfucker trump will all of a sudden decide the government is in the shipping business as soon as this blows up in red states he thinks are a guaranteed win for him in November.
Cheryl Rofer
@Cermet:
WhoaWhoaWhoa! We don’t know that. The evidence so far is that people who recover are immune, but we don’t know for how long. Immunities to other viruses are temporary.
I see Fair Economist has addressed the mutation question. A biochemist friend tells me that SARS-CoV-2 is pretty robust to mutation, so that seems not to be a big worry from what we know.
Suzanne
@zzyzx: Agreed. I am increasingly convinced that we are going to have massive civil unrest if these orders last more than, say, three to four weeks. Look at how gun sales are spiking.
wvng
@MomSense: we CAN’T be too successful at social distancing. That behavior provides the space for several things to happen. First, catching up with testing so that we could begin the case isolation and contact tracing routine that has worked so well in Singapore to reduce infections. Second, it provides spaces for medical interventions to be developed and eventually a vaccine.
Robmassing
Thank you for this
snoey
@Cheryl Rofer:
The tools are the same.
Suppression is attempting to ring fence a small outbreak before it becomes an epidemic – like we do when Ebola breaks out again.
Mitigation is doing what we can to prevent the epidemic from being worse.
Fair Economist
@Cheryl Rofer: I like the “suppression” terminology because the two terms used in discussion before the paper were “mitigation” and “containment” – neither of which is a functional policy now. “Suppression” is IMO a clear description of the best available policy – reduce the disease to a very low level.
To me the distinction is clear because “mitigation” gets used in the health care literature a fair amount, in the context of ideas like “harm reduction” where the goal is to reduce the damage from something even though we have to live with it at a fairly high level. YMMV.
Cheryl Rofer
@snoey: Thanks! Yes, those are the definitions I keep reading and that keep slipping out of my head because I don’t see their utility in our current situation.
That’s not quite true – There are still parts of the US and the world that have few cases, and where suppression might work. But overall, we need to do everything.
@Fair Economist: I don’t read the health care literature regularly, so those words are unfamiliar to me and thus not helpful.
I think it’s worth thinking about what comes after the summer peak, but this is a long post by itself. Maybe later.
BruceFromOhio
@snoey: that is a very useful site, thank you for sharing! And thanks to daughter ID doctor.
Sloane Ranger
A question about the US health system. In the UK, theoretically at least, if an ICU bed is not available at the hospital where you are taken, you can be moved to one where there is a bed, all at no cost to you.
What would be the position in the States if the hospital where you were taken didn’t accept your insurance or, even worse, they did take your insurance but there was no bed but there was a bed in a nearby hospital that didn’t accept your insurance?
And what about the uninsured? Could the government, State or Federal order hospitals to treat people regardless of their insurance status and guarantee payment? If so, what would it take?
Sorry if the question seems naive but I really don’t understand your system.
Elizabelle
@Sloane Ranger:
Nor do the people that “run” it or fund it. You raise great questions.
I think we will get a better healthcare system out of this pandemic. Down the road. The present one is too damn cruel, expensive, and inadequate.
p.a.
Our system is easy to understand: haven’t you ever been to a casino?
p.a.
@Elizabelle: yes, it’s time for some DISASTER
SOCIALISMPROGRESSIVISMSuzanne
@Sloane Ranger: In practice, most hospitals accept most insurance plans that are common in their area, so that scenario doesn’t occur too often. It gets more dicey when you cross state lines.
Hospitals are liable if someone comes in who is sick and the hospital transfers them out somewhere and then the patient dies. So, in practice, most hospitals will care for that patient, write off the bill…. and then jack up the cost for everyone else.
FelonyGovt
LA County is throwing in the towel on COVID-19 testing. How will that skew the model and the numbers?
snoey
@BruceFromOhio: @Sandia Blanca: @O. Felix Culpa:
Thank them.
They wrote it to be read, please share then link wherever it might be useful.
Eunicecycle
@snoey: That is great! I also enjoyed the little humor thrown in, like Are you a sword swallower? in the flow chart.
Ruckus
@E.:
I’ve owned 2 small businesses. Owned as in past tense. Lost one to natural disaster and one to republican economic disaster. A lot depends on how you respond and what kind of disaster it is. With one like this that involves everyone and what they do in response, all you can do is carry on. In both the above events my landlords actually helped me. Yes it wasn’t enough but it was a helping hand and in reality it didn’t really harm them. If we could bound and gag the republicans in congress we could actually make this disaster livable for small business – and big business, the bills have already passed. OK I’m out now. One thing that is different and that is that no one is immune to the effects of this. So we have a chance to actually come out the other side with, yes a different looking economy, but yes one that might actually be better.
Good luck.
susanna
@KnowLittle: Thank you – long and useful to evaluate future possibilities. And to plan for the long run
Cheryl, thank you! And to snoey for helpful, concise information.
I’m thinking we’re going to be inundated with all sorts of mixed messages and with a lack of competence at the top, there’s going to be a need for top evaluative and substantial, trustworthy information, or we might literally become a giant melting pot.
FelonyGovt
My link re LA County health testing didn’t come through, here it is https://www.latimes.com/california/story/2020-03-20/coronavirus-county-doctors-containment-testing?_amp=true&__twitter_impression=true
Brachiator
@Cheryl Rofer:
Great post. The numbers of possible numbers of people affected by the virus are very sobering.
It is becoming clear that we are not talking about a conventional recession, or conventional stimulus, when we are deliberately contracting the economy. But various countries are coming to a consensus about methods to try to help people maintain.
More on this, I guess, in a thread about the economy. But you are right that Congress needs to get moving. Still, I am cheesed off that the Republicans in general, and Trump in particular, want to make corporations the center of attention, and are even trying to sneak in more corporate tax cuts.
But I am also majorly cheesed that Schumer is so fixated on simply expanding existing programs.
I want to see a speedy response, but also some innovative thinking.
Frankensteinbeck
@Cheryl Rofer:
As McConnell’s telling his caucus to swallow their nausea and vote for the leave bill demonstrates, he absofuckinglutely hates helping people. He is getting off on the prospect of watching millions of poor people die. If this weren’t electoral poison and bad for his corporate donors he would be dancing in an empty street celebrating the misery. The man glows with beatific joy every time he talks about destroying the social safety net. And his caucus aren’t that far behind.
This is electoral poison and his corporate masters do hate the annihilation of the economy involved, but turtle will drag his feet and quibble in the hopes of maximizing deaths without ruining his chances for reelection.
no comment
@Fair Economist:
Is the loss of immunity to the exact same cold virus? Meaning re-exposure would be necessary to maintain immunity for a longer period of time? Or is the problem that the cold virus mutates too quickly and the second exposure is to a similar but distinct cold virus? A bit of both?
I’m mainly wondering what are the challenges of coronaviruses in general that have made developing vaccines so difficult?
I skimmed the Wikipedia article about coronaviruses to see if I could answer my own questions, but unless I skipped over it, the article didn’t explain why there is a problem developing a vaccine to any previous coronavirus.
Cermet
@Cheryl Rofer: I agree that a mutated strain will reinfect people. I am saying the current strain will, in all likelihood, not reinfect people. Wether a mutated strain will cause as serious an illness – from past flu’s – the answer is generally no (but the socalled spanish flu did not do this – it got far deadlier.)
I am NOT gonna want to believe the later event simply because of what that will mean and will prefer/believe that the next mutate strain is less deadly (though infection rate will likely be similar.)
germy
https://accrispin.blogspot.com/2020/03/writer-beware-in-time-of-coronavirus.html
Fair Economist
@no comment: Yes, they did experiments inoculating volunteers with one particular strain of common cold coronavirus. They also tested antibody levels and they fell over time. After a year the antibody levels were about where they were at the start (remember it is ubiquitous and so everybody has antibodies to this strain); however only about 1/3 of volunteers inoculated a year later got it again, so there is something going on besides antibodies to provide protection.
The reason we don’t have a common cold vaccine is that there are literally hundreds of different viruses in several very different groups that cause “colds”. You’d need a vaccine for each, and you’d probably need to be re-vaccinated every couple of years for each one. You’d need dozens of shots per year, and between the cost and the hassle it’s not really worth it.
germy
@Frankensteinbeck:
I don’t know. I think his and his colleagues worldview is that government shouldn’t be in the business of “helping” people in distress. Private charity from churches, etc. should handle those duties.
I disagree with him, but I think that’s his idea of government’s role: Provide people like him with years of employment, smooth things over for corporations and industry, fight the “Democrat party” and that’s about it.
Cheryl Rofer
@Cermet: My point is that you are being more certain than I am about several things. There are reasons to believe that they may be true, but I think we have to be VERY careful now in distinguishing what we know through scientific study and what seems likely.
I’d like to see further modeling of some of these possibilities. Maybe in a bit.
gwangung
@germy:
Fuckers like him forget that this is a SYSTEM. You can’t prop up one part; you need to do it all, at the same time, or the disruptions will overwhelm the props.
germy
@gwangung: He sees that as “collectivism.” That’s my guess, anyway. The only system he recognizes is the one that props up his wife and himself.
Frankensteinbeck
@germy:
I think that’s common in his allies, and it’s the official party line, but you don’t get even that far without being either extremely naive – which McConnell isn’t – or have a serious mean streak already. Between McConnell’s southern patrician upbringing, his being the first to go ‘he must be stopped’ ballistic when Obama was elected, the only things he’s fought for (obstruction is easy) being destroying the safety net and slashing rich people’s taxes, and particularly the fact that he only smiles and looks happy when he’s talking about doing something utterly assholish, I am convinced he is one sadistic, racist motherfucker who considers everyone who isn’t a rich white aristocrat vermin that deserve to suffer for electing a black man president.
ziggy
I”m watching what is happening in my state (Washington), and now I’m getting a picture of how flattening the curve could actually help the economy tremendously. It appears that as testing is ramping up, the proportion of positive tests is actually falling in Washington, which is great news. This means that we are not seeing the explosive growth of the virus that is happening in other states like New York and California. Here’s where I got this info from, but I’d like to see other confirmation that this is the case:
https://cliffmass.blogspot.com/
I believe that this is why we are not getting a “shelter in place” edict like we have seen in other states, but we are right on the edge and it could happen any day now.
Having the ability to work (outside), go to my suppliers (with very changed routines/hours) and eat out (drive through/take out) is HUGE for me, and if you multiply it times tens or hundreds of thousands that is going to have a huge effect on the economy. I am crossing my fingers and toes every day that I can keep on working. If we can avoid a total shutdown, it will be a lifesaver for so many.
As we who are not so vulnerable are moving about society on a limited basis, we are still going to get sick, get well, and eventually be able to provide some herd immunity. But we can do that without exposing too many of the elderly and other vulnerable people who are much more likely to need hospitalization and have high mortality. Thus we can get to that golden stage of herd immunity and vaccine availability, with much less severe illness, mortality, and a much less severe economic strain on the population. It is a delicate balancing act of how much to tamp down.
Anyway, that is my positive spin on the theory of flattening the curve. We will see how it plays out in my state and all the others.
Martin
@Brachiator: The benefit of expanding existing programs, at a time when lots of government workers can’t be at work and design programs, is that all of the infrastructure and rules for those programs are already in place. Expanding them gets them operationalized very quickly. In some cases immediately.
As someone who has ramped up a lot of government programs really quickly, a good formula is:
Each one makes the next one easier to implement or reduces the size of it. Trump is trying to do 5 while still struggling with 1. Schumer is trying to do 3 because 1 and 2 are the job of the executive branch not the legislative.
You almost always need to do all of them. So doing 3 doesn’t preclude doing 5.
trollhattan
@snoey:
That is a very good resource. Hat tip to your daughter–hope she stays safe!
germy
germy
@Frankensteinbeck:
No argument from me there.
wenchacha
@Cheryl Rofer: can you address the issue of the recurrence of the virus in the Fall or whenever? I’m the case of the 1917-18 flu pandemic, stories say it was “more lethal” in the 2nd round. Because of some mutation?
Same sort of question with our novel coronavirus: is there reason to suspect it to become more dangerous? I can also understand that public behavior may resist long-lasting restrictions, and that resulting in viral spread.
I know you’re not a virus expert, but maybe you know this stuff. Thanks!
zzyzx
@ziggy:
There is actually very little difference between shelter in place and what WA is doing.
Unless you mean the Italy style lockdown… I wonder if we’ll be spared from that in some degree due to our lack of urbanism. Having space between houses might save us.
HinTN
@rikyrah: I used my first pair of gloves today for precisely that action. Timely!!!
Brachiator
@Martin:
You have noted this before in earlier threads. You overstate the “speed” of using existing programs.
You also overlook the fact that some of these existing programs do not fit the current situation. A check on April 8 for someone still employed is better than waiting until that person is laid off and has to file for unemployment to get money.
The growing consensus from other countries is to look at what is needed for the current situation, even if it means coming up with new programs and ways of getting help to people.
trollhattan
Yesterday’s “Science in Action” on BBC World Service had a couple of interesting takeaways for me:
–An Italian epidemiologist who so happens to be on sabbatical in an Italian village helped set up a program to test all 3,000+ inhabitants. The positives were 75/25% asymptomatic/symptomatic. They quarantined them all, then retested (I forget after how many days) and only found three more positives.
This approach works and I can only hope that while we’re unlikely to have 100% testing, because Freedom, that 100% testing occurs before allowing anybody back to work or school.
–A university in the US (forget who) has created a blood test for antibodies that they are now sharing with labs around the country. It can be automated using common lab equipment so hopefully will soon give us the third vital data stream: who has already recovered from the virus such that the virus test is negative? They are already using it to choose medical staff for treating active cases. Smart.
Cheryl Rofer
@wenchacha: As I’m reading the comments on this post, I’m thinking that another post on what may happen after the summer peak may be a good idea. It will be even more speculative than this one. It would, probably, mostly enumerate the factors that will come into play and what we don’t know about them.
I think there are ways through to a soft landing. A first step is to ignore Trump and his Coronavirus Show, and it looks like that is starting to happen.
HinTN
@Fair Economist:
That is good to know (and somewhat comforting).
trollhattan
@zzyzx:
It could revolve around how willing folks are to follow non-binding stay-in-place directives. Australia was just forced to close their beaches because a stretch of warm weather had folks hitting them in the thousands. Yesterday. “Crikey, no bug is going to get me, mate. Just look at all these Sheilas!” (See also: Florida spring break.)
L85NJGT
@wenchacha:
Probably antigen drift. The third wave was as lethal as the second wave, but had lesser impact as they were no longer shipping soldiers around the planet and plowing forward with war production.
ziggy
@zzyzx: My understanding is that “non-essential” workers are supposed to stay home. Is that not the case in California and New York?
HinTN
@Fair Economist: deleted repeat
L85NJGT
@HinTN:
OTOH they are more difficult for vaccines.
There is probably some antiviral drug cocktail that would\will help, but that takes time and controlled trials. The argle-bargle about synthetic Quinine was completely useless.
Martin
@Cheryl Rofer: And it’s not just mutation to worry about. Lots of diseases don’t confer lifetime immunity. That’s why measles is so pernicious – it resets the immunity of almost all other illnesses, setting you back to zero.
That’s why we need boosters for some illnesses. And you have things like chickenpox which has a vaccine, but if you catch it you now get a different illness requiring a different vaccine.
Viruses can do some funky things.
wenchacha
@Cheryl Rofer: Thanks again. The information you share is really helpful, even if it isn’t always pleasant.
Kattails
@Cheryl Rofer: (or anyone), slightly side question. As an older person with asthma, I got the pneumonia vaccine. It looks like one of the big issues with those with a severe reaction to this coronavirus is actually a secondary pneumonia setting in, which seems to be opportunistic. Just wondering whether that vaccine is likely to be of some help in mitigating the worst effects of this. Hey, anything that helps even a tiny bit…
snoey
@Kattails: The pneumonia isn’t secondary, it’s the virus moving to the lungs instead of just being an upper respiratory infection.
Not having another lung infection at the same time would be a very good thing.
no comment
@Fair Economist:
Thanks for replying!
I was guessing that the mild symptoms of a cold (in the vast majority of people) and the cost of developing a vaccine was just as much an issue as the number of different cold viruses and possible need for booster shots.
I am hopeful that all the factors that make COVID-19 a serious threat (mortality rate, longer incubation period, longer period of contagiousness, etc.) mean that researchers will get funding & resources needed to develop a vaccine.
Ksmiami
@Frankensteinbeck: He’s first against the wall in my book.
Kattails
@snoey: Thanks, now I understand. Your linked post was very well done, clear, helpful, I’ll pass it around. Many thanks.
Many thanks to Cheryl as always.
planetjanet
Thank you, Cheryl. Your posting is refreshingly clear and objective. I feel smarter after reading you.
BroD
@MomSense:
As I understand it, herd Immunity is achieved via culling.
just sayin’
debbie
@snoey:
Just seeing your link now. Thanks for the great information!
Another Scott
@Sloane Ranger: One of the previous emergency bills passed by Congress and signed by Donnie said that testing is free. There are proposals in the House for the “3rd stage” bill to include free treatment. I doubt that is in Moscow Mitch’s bill that he wants to ram through on Monday. We’ll see what the final bill is… (Of course, if this recession/depression/emergency is as bad as many fear, then more legislation will be needed.)
There’s Reagan-era laws that US hospitals have to try to save your life if you show up at the emergency room independent of your ability to pay. That can mean that they stabilize you long enough to transfer you somewhere else… :-( And bill you when you leave. They don’t have to treat chronic conditions or not-immediately-life-threatening conditions.
HTH a little.
Cheers,
Scott.
Bill Arnold
@BroD:
AKA “Mountains of Corpses”, in the “we’re overreacting” responses argued for by young right wing techbro types, who will inherit money if their parents die. (Oh, did I type that?)
Bill Arnold
@Frankensteinbeck:
And he seems to take delight in negative reactions to his behavior.
It almost makes me sorry that his injury incurred in a trip-and-fall last August wasn’t more severe.
McConnell underwent surgery for shoulder fracture (Veronica Stracqualursi, Phil Mattingly, August 16, 2019)