This will be the final post in the series, so I want to extend a big thanks to Carlo for sharing both his knowledge and his thinking on AI with us!
Between the holiday break and some work deadlines and all the craziness, we’ve had some distractions that have made finding the right time for this final post a bit more complicated. There has not been one complaint (not that I have seen, at least) about the delay, so I’m hoping that maybe this is better timing for all of us!
Thanks again, Carlo!
Guest post series from *Carlo Graziani.

On Artificial Intelligence
Hello, Jackals, welcome back. Happy New Year, and thank you again for this opportunity. Being able to write these posts on AI has been very helpful to me, because writing this stuff out in a manner suitable for exposition has really forced me to clarify my own views on AI, and has allowed me to be much more exact and specific on both what my objections to the AI enterprise are, and on what the value of that enterprise is. Basically I’m in a better place to tell the baby from the bathwater, thanks to this series.
This is the last post in the series. I have more-or-less emptied the bag of technical matters concerning AI which I think I understand that most people don’t, and having done that, it’s time for me to summarize the content of the past six posts, and to use that summary to try to understand where we are on AI today, and where we are likely going, at least in the near future.
Again, you have my gratitude for reading, and for the very high level of the comments that have followed each of the previous posts. BJ really is a unique, special place.
Part 7: The Coming AI Winter
Let’s start out with a very high-level summary of where we’ve been in this series.
AI and Learning
At several points in this series, I pointed out that all “AI” is in fact a form of statistical learning, and introduced the Statistical Learning Catechism, which states that what every such system does is the following:
- Take a set of data, and infer an approximation to the statistical distribution from which the data was sampled;
- Data could be images, weather states, protein structures, text…
- At the same time, optimize some decision-choosing rule in a space of such decisions, exploiting the learned distribution;
- A decision could be the forecast of a temperature, or a label assignment to a picture, or the next move of a robot in a biochemistry lab, or a policy, or a response to a text prompt…
- Now when presented with a new set of data samples, produce the decisions appropriate to each one, using facts about the data distribution and about the decision optimality criteria inferred in parts 1. and 2.
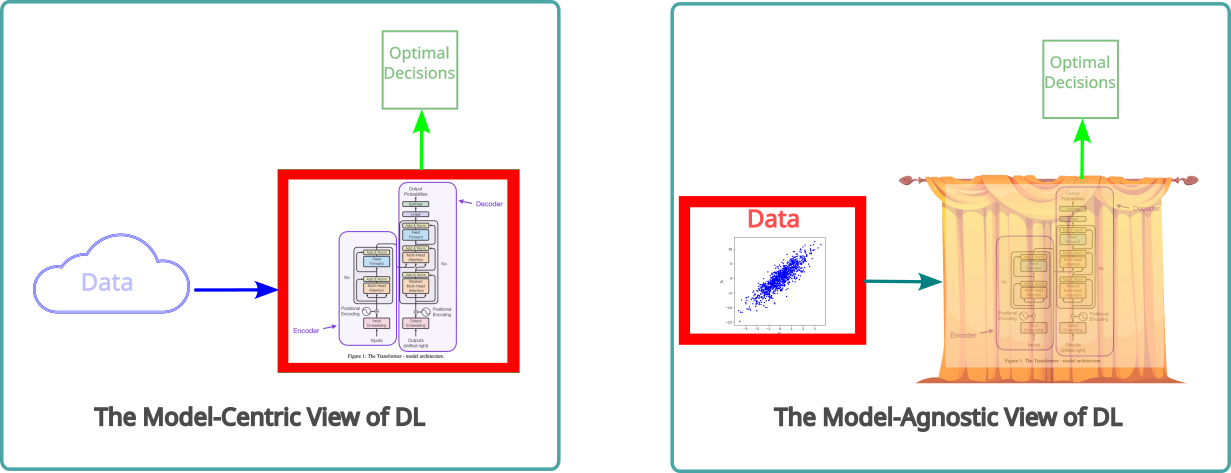
It is worth emphasizing, again, that this is all that is going on in any AI system, including all Large Language Models (LLMs). It’s basically just pattern recognition coupled to decision-making: if you can model how you would have made reasonable decisions based on past data, you can use that model to make reasonable new decisions based on new data.
The fundamental simplicity of this scheme belies the power of the methods that it enables when coupled to modern computing. Academic computer scientists were the first to realize the possibilities inherent in that coupling. In 2007, they began to show that many learning problems previously regarded as intractable could be easily solved using a set of computational techniques based on neural network models that came to be known as “Deep Learning”. Examples of such problems are image classification, voice recognition, protein structure prediction, materials properties prediction, empirical weather forecasting, and, beginning in 2017, natural language processing. The last one, brought about by the advent of a type of DL model called a “transformer”, marks the arrival of LLMs, and the beginning of what most people nowadays think of as “AI”.
The Role of the Tech Industry
The choice of the term “Artificial Intelligence” to describe this subject is misleading, however. AI is nothing but statistical learning, and learning is a very limited aspect of human cognition, not being remotely sufficient to model “intelligence”. After all, even single-celled animals “learn”. The impressive parlor tricks that can be performed by LLM-based chatbots should not deceive us into anthropomorphic intepretations of their workings. They are by no stretch of the imagination “Intelligent”.