Martin has been kind enough to put together a Guest Post on Data Modeling in the Epidemic. Part 1 was posted at approximate 2:30 pm on Wednesday. This is Part 2.
Once again, Martin is standing by in case we have questions.
Take it away, Martin!
Questions on Data Modeling in the Epidemic: Part 2
So, how do we know if containment is working and for how long do we need to do this?
We can answer this! Well, we can get close, with a few caveats, because we can look at what happened in China, and we can do a little bit to confirm that model with what’s happening in Italy a bit ahead of us. So how do we build it?
Well, what do we have to work with, and what do we need to know? We have a few data elements – confirmed cases, fatalities, recoveries. And we have time. We know this data for each day. We know this for the whole world, for different countries, and for different cities and states. Now, the experts have a whole bunch of other data, hospitaliation, ICU cases, intubated cases, tests administered but waiting on results, etc. and all in infinitely more detail than we have.
Confirmed cases is kind of garbage. I’ve been largely ignoring it because I don’t know if it’s telling me reproduction rate R0 or testing rate. It may get reliable, but I’m not counting on it.
The most accurate bit of data is likely fatalities. Unlike determining if someone is infected or not, we’re really good at determining if someone is dead or not. And if they are dead, we can test if they’re infected, so we can probably rely at this point on that being a pretty reliable number. Time can be a bit more uncertain than you might think because when data is collected and reported in a human administrative dependent process (as opposed to an automated weather station that does things on precise and unwavering schedules) you have problems of people going to the dentist and not getting their data in until the next day. So, we’ll expect this to be a bit noisy from day to day.
Now, because we’re at the start of an epidemic, where there’s almost nothing holding spread back like herd immunity, we can probably expect to see something like a perfect exponential curve. A model for infected is more complicated because people recover. Nobody recovers in our model. And when we plot that out, that’s exactly what we get. People aren’t very good at intuiting variation from an exponential curve, or even extrapolating on an exponential curve, but if you take the logarithm of your data, you wind up with a straight line, and we’re pretty good at intuiting a linear function. Below is a plot of the log of our fatality data for the US, and that’s a pretty darn straight line. I suspect that recent uptick in the slope is due to NYC dominating the national data and having a higher R0.
If you want to play along at home, the fatality rate for the US is approximated by e0.273t where t is days since the first fatality (Feb 29).
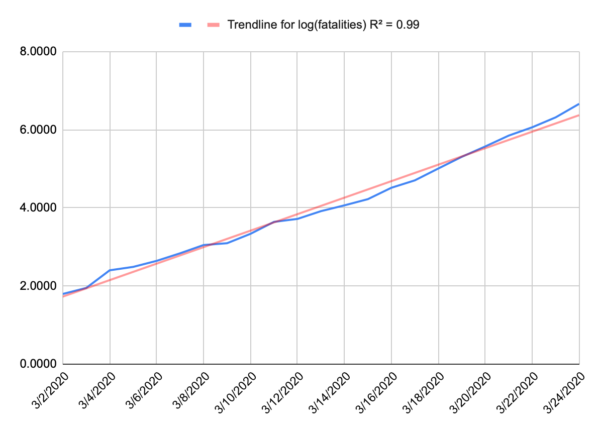
So we have a well behaved exponential function, and that doesn’t tell us when things will change, but it does give us a sense of urgency. You can look forward and see projected fatalities that make you pucker and decide let’s make sure we don’t get there and then work backward.
Understand, we’re building a very simplified model here. Our goal isn’t to give us any real long-term predictive value of how many people may contract this, or how many people will die. Our goal is to give a good approximation of the worst case sceniario for early in this epidemic and then look for when the model breaks on the assumption that our actions will break the model before other normal factors like herd immunity does. The model gives us a sense that if we want to keep fatalities below a certain number (and we’re assuming that number is relatively small) then we need to act before a certain date. In terms of actual fatalities, the model is probably accurate to about an order of magnitude, and that’s all we’re looking for. Are we looking at thousands or tens of thousands or hundreds of thousands of fatalities? What should I emotionally try to prepare myself for, and how loudly should I scream at my governor to shut my state down now, even if things may not seem too bad locally.
What does China tell us?
China gives us some good data to work from. They did a bunch of minor things just as the US did, but they locked down Wuhan on Jan 23, and all other urban areas the next day. Jan 23 is our day 0. And China saw a nice exponential curve as well – it was a little different in magnitude (the slope of the log is different) so it might grow a bit faster or a bit slower but either way it grows incredibly fast.
The first sign their lockdown was working was on Feb 5 (day 13). That was the first day that new cases fell, and they generally continued to fall after that. That doesn’t mean that people stopped getting sick on Feb 5, it means they stopped getting sick on Jan 24, but we couldn’t measure it until 13 days later (give or take a few days, plus a few days to confirm that it’s a trend and not just an outlier). So, if we are modeling infections and we want to know if a given action had an effect, measure any change that occurs around the 13 day mark. That also tells us that any action needs to remain in place for probably around 3 weeks before we get any real sign it is working or not. But this is our inflection point for R0 going from greater than 1 to less than 1.
The next sign came on Feb 13 (day 21), the first indication that the rate of fatalities was halting. Now, the fatalities didn’t immediately fall, but it stopped growing and that’s key. Fatalities per day stayed relatively flat until Feb 24 (day 32) when it started to consistently fall. Then on March 9 (day 46) the number of daily fatalities fell to about the level of day 0.
So, what does this tell us? Well, look at that date where the fatality projection makes you pucker, go back 21 days and make sure your most aggressive mitigation action is in place by then, because if not, you will hit that number, and you may maintain that daily rate of fatalities for days.
Now, a few caveats here. The 13 day and 21 day numbers are largely a function of the virus, and not the population. Those should be roughly equally true in China as New York City as Montana. If you blow through day 13 (give or take) and have no reduction in infections, then you didn’t dream big enough, need to throw down some much more restrictive actions, and wait another 13 days (give or take).
So, does Italy validate that? Possibly. Italy quarantined their first area on Feb 23 and then did national quarantines on March 8/9. We should see some slowing of new cases on March 7 (day 13 for the smaller area) but without an infection model we can’t see that, and a larger reduction around March 21/22 (day 13), and we did see that on March 22. We should also see some sign of reduction in the fatality numbers around March 15 (day 21 for the smaller area), and we do. Their numbers are still climbing, because that wasn’t the national lockdown, but it definitely slowed right around that date. The next and larger data point should come around March 29/30.
The dates after that are largely a function of the population, the effectiveness of the actions taken on day 0 and the compliance of the population. The 11 day long plateau in the fatality rate that China saw might be shorter or longer here. The 14 days to reduce from the plateau back to day 0 might be shorter or longer here.
My assumption is everything will be longer in the US than China. Despite Wuhans high population density, China has an unprecedented ability to control their population and an unusually high level of compliance by the public. The US is struggling with compliance, and has very little control. That doesn’t mean it won’t work, it just means we probably won’t see that nice sharp inflection that China had. It’ll probably be messier and slower, possibly much slower. Italy should give us a little more insight in how much things can vary. Their lockdown was national, but Italians are notoriously defiant of government guidelines, so they should look closer to US efforts.
Days 0 in the US:
Bay Area: March 16
California: March 19
New Jersey: March 21
NYC: March 22
Bay area is already showing some evidence of improvement, presumably from their work from home, public gathering orders back in early March. We’d expect to see real new case declines on or just after March 29. CA as a whole, April 2, New Jersey April 4, NYC April 5. We’d expect to see fatality growth halt in the Bay Area on or after April 7, CA April 10, NJ April 12, NYC April 13.
If nothing else, we’re trying to establish the importance of acting quickly because once fatalities starts to go, it goes fast. And while we’re in this state just waiting for something to happen, roughly when we can expect to see results and where to look.
Additional information added at 3pm, based on new information and an additional model:
So, I wrote this yesterday, and some new information has come out, and some new models have been made.
Specifically, I built a model of NY. To start, it’s a bad model since there are only 13 days of fatality data. A model built on 13 datapoint is going to suck. It can change wildly with just one more data point. To give an example, a model built of Washington State built after 13 days would look apocalyptic because all of the data was dominated by a single nursing home, that you would expect to have a vastly higher mortality rate than the general population. The mode suggests a trend that simply can’t hold, mainly because everyone in the nursing home was pretty much accounted for. You can’t grow fatalities in a 150 person facility above 150, but the model is too primitive to reflect that. So that’s just a limitation we need to keep in mind. And sure enough, after some more data was collected, a more reasonable and less apocalyptic trend developed. We just had to be aware that there were a lot of unknowns and wait to see how things shook out. That how this kind of field data modeling works. It’s messy and limited but can help to tell us where to look or can change the urgency of a decision.
As to New York, their numbers look pretty apocalyptic right now. But New York isn’t getting the kind of detailed reporting that Washington did. For all we know, most of these fatalities came out of a single project in the city and once it tears through the few thousand people that live there, the underlying general population trend will emerge. I’m hoping that’s the case, but we just have to wait. I want my model to break, because that provides us with a new bit of information, and we can then go and try and figure out why it broke. We have a theory for when lockdowns will break the model, but there can be other causes as well – as happened in Washington state. That’s not a bad thing. In fact, that’s sort of the point.
Another key bit of information is out of Italy that they may be significantly underreporting their fatalities. That was a concern of mine. Any human collected dataset has to deal with this stuff, so you just asterisk everything. The testing data is kind of garbage because everyone has different access to tests, and different criteria for testing, but it also changes for a given location. When the 10th person this hour walks in presenting the same set of Covid symptoms, do you really take the time to give the test, or do you just get them in a bed ASAP. Of course testing is good information, but you may no longer feel you have time to do it. So testing data just gets that much more unreliable. Same goes for fatalities. When 13 people a day are dying in your hospital, the effort you put into determining cause of death is going to change. Do you run the Covid test so you can list that as cause of death, or do you just put down what you know, respiratory failure, and move on.
Italy’s fatality data seemed to fall off faster than I expected. I attributed that to the smaller quarantine in northern Italy having an oversized effect on the data (they quarantined for a reason, so it’s not unreasonable to assume they’d dominate the data) but now it’s looking like it may (also?) be a lack of attribution of fatalities to the disease. We just have to deal with that. China’s data saw a similar pattern, possibly for a similar reason. Maybe fatalities don’t drop off at day 21, hospitals simply get too overwhelmed to count them accurately, and the real dropoff is day 32. More likely it would be somewhere in between. So, we’ll look more closely at Italy’s data as it continues to come in and see if we can figure that out. California may provide a better data point. We locked down earlier than Italy in terms of number of fatalities, so I don’t expect CA will get quite as overwhelmed as Italy. That should give us somewhat more consistent data.
 Respite Open Thread: Unplugging For Your Health
Respite Open Thread: Unplugging For Your Health
dmsilev
Florida: Some time in the vaguely indefinite but hopefully near future.
Texas: Ditto.
Etc.
Sigh.
(though, in both cases, cities have acted even when the state government refuses to. And they’re not quite as insane as the state government in Mississippi, which is actually trying to override local “shut things down” orders)
trollhattan
Thanks again Martin. I will need to read 2x, that’s how my brain is constructed.
Peering at the Hopkins page it would seem Italy will pass China in total cases within a few hours and before the US also does. A scary thing for me is once this plows into the developing world their infection and death counts will zoom past all these reporting nations and nobody will have a handle on the statistics, because they lack the infrastructure to collect data.
BR
Here’s the problem — the numbers for COVID-19 deaths may be wildly off. Here’s Josh Marshall this morning:
https://talkingpointsmemo.com/edblog/this-is-very-important-from-italy-please-read
Kent
My wife is a physician and currently working as the regional COVID coordinator for Kaiser Permanente in Clark County WA (Vancouver area). She says don’t trust the death figures either. They are having elderly patients die of respiratory failure without ever having been tested. I don’t know if the coroners office is doing post-mortem COVID testing. Probably not.
What Have the Romans Ever Done for Us?
How is Seattle/Washington State doing? Weren’t they first on the curve and if so shouldn’t we be seeing evidence that it’s working (or not)? Presumably their compliance would be about on par with most other U.S. based locales. Maybe not NYC because that is in a class of its own in terms of population density, but cities like Philly, Denver, Indianapolis, etc. are probably not much different than Seattle density-wise.
lee
@dmsilev: I read about Mississippi today. It seems at least the state has stopped trying to override the local mandates but the state is doing very little to stop the spread.
When this is all said and done, it will be very interesting to see the data from the various states and the various areas of each state.
Martin
So, I wrote this yesterday, and some new information has come out, and some new models have been made.
Specifically, I built a model of NY. To start, it’s a bad model since there are only 13 days of fatality data. A model built on 13 datapoint is going to suck. It can change wildly with just one more data point. To give an example, a model built of Washington State built after 13 days would look apocalyptic because all of the data was dominated by a single nursing home, that you would expect to have a vastly higher mortality rate than the general population. The mode suggests a trend that simply can’t hold, mainly because everyone in the nursing home was pretty much accounted for. You can’t grow fatalities in a 150 person facility above 150, but the model is too primitive to reflect that. So that’s just a limitation we need to keep in mind. And sure enough, after some more data was collected, a more reasonable and less apocalyptic trend developed. We just had to be aware that there were a lot of unknowns and wait to see how things shook out. That how this kind of field data modeling works. It’s messy and limited but can help to tell us where to look or can change the urgency of a decision.
As to New York, their numbers look pretty apocalyptic right now. But New York isn’t getting the kind of detailed reporting that Washington did. For all we know, most of these fatalities came out of a single project in the city and once it tears through the few thousand people that live there, the underlying general population trend will emerge. I’m hoping that’s the case, but we just have to wait. I want my model to break, because that provides us with a new bit of information, and we can then go and try and figure out why it broke. We have a theory for when lockdowns will break the model, but there can be other causes as well – as happened in Washington state. That’s not a bad thing. In fact, that’s sort of the point.
Another key bit of information is out of Italy that they may be significantly underreporting their fatalities. That was a concern of mine. Any human collected dataset has to deal with this stuff, so you just asterisk everything. The testing data is kind of garbage because everyone has different access to tests, and different criteria for testing, but it also changes for a given location. When the 10th person this hour walks in presenting the same set of Covid symptoms, do you really take the time to give the test, or do you just get them in a bed ASAP. Of course testing is good information, but you may no longer feel you have time to do it. So testing data just gets that much more unreliable. Same goes for fatalities. When 13 people a day are dying in your hospital, the effort you put into determining cause of death is going to change. Do you run the Covid test so you can list that as cause of death, or do you just put down what you know, respiratory failure, and move on.
Italy’s fatality data seemed to fall off faster than I expected. I attributed that to the smaller quarantine in northern Italy having an oversized effect on the data (they quarantined for a reason, so it’s not unreasonable to assume they’d dominate the data) but now it’s looking like it may (also?) be a lack of attribution of fatalities to the disease. We just have to deal with that. China’s data saw a similar pattern, possibly for a similar reason. Maybe fatalities don’t drop off at day 21, hospitals simply get too overwhelmed to count them accurately, and the real dropoff is day 32. More likely it would be somewhere in between. So, we’ll look more closely at Italy’s data as it continues to come in and see if we can figure that out. California may provide a better data point. We locked down earlier than Italy in terms of number of fatalities, so I don’t expect CA will get quite as overwhelmed as Italy. That should give us somewhat more consistent data.
eric
@trollhattan: mexico city and rio are going to be unimaginable.
lee
@BR: Some (but certainly not all) of those additional deaths might be individuals who needed constant care to stay alive. With resources stretched so thin, they couldn’t get the care they needed.
@Kent: Hopefully they at least took blood, tissue, etc samples and once things slow down they can test them.
Martin
@trollhattan: We’re only behind Italy due to a lack of testing. We are simply a larger country so we would expect a larger case count.
That said, China is a MUCH larger country so it shows how effective their very early lockdown was. They locked down before where Florida is right now.
I suspect Ohio might be the brightest spot in the nation when this is all over. They did act very proactively.
lee
@eric: I read that the drug gangs are imposing an 8pm curfew in some of the favelas. I guess that is better than nothing which is what their Trumpian President is doing.
Martin
@What Have the Romans Ever Done for Us?: Unfortunately Washington locked down after CA. Everett was the first city on 3/21. The state on 3/23.
eric
@lee: i saw that. I think mexico city will be apocalyptic
West of the Rockies
Thank you, Martin. This has been informative; it also offers reasons to hope (to hope more states pursue social distancing rules, to hope states like California see the same decrease as other places that established rules).
Cheryl Rofer
@Martin: Love this!
Also, I love this website! It’s a visualization of several parameters indicating the extent of the epidemic for countries and states. Can see them in linear or logarithmic plots and pull one country or state out of the group.
joel hanes
@Martin:
significantly underreporting their fatalities.
I’ve seen suggestions to look at the reported deaths from pneumonia, subtract the trailing multi-year seasonal average, and add that to the COVID-19 fatality figures.
trollhattan
@eric:
Top of my list of Dear God they do not deserve this are those living in the enormous Syrian refugee camps. I’m sure Assad and Russia have halted their silly hospital bombing campaign as a humanitarian gesture, right? Not that that would help, at this point.
Chris Johnson
I do not like the way your plot, on top of the log, hints at being like an exponential function ON TOP of already being a logarithmic function. I already keep track of trend lines as far as running my (internet-based) business and your modeling isn’t unfamiliar with me, but I really REALLY don’t like the faint curve in there.
I think I have a basic sense of where it’s coming from: our fearless leaders doing their best to straight up kill us, and even more than that, the useful idiots out there doing their best to own the libs by giving everybody the ‘imaginary flu’, and on top of all those things our basic corporate/capitalist system working as designed, to keep all its humans grinding away at top capacity and stressed too hard to fight back, plus taking another share of capital out of the health care needs of those humans.
I do get it. I see how this is happening.
I do not like that small, perceptible curve on top of the logarithmic curve. I don’t think we’re going to be able to stop it before all hell breaks loose (like it isn’t :P )
Kent
I suspect this is going to follow population centers rather than state boundaries. Washington really has 3 main population centers that are all widely separated. (1) Puget Sound which is the greater Seattle area, (2) Vancouver, which is really just suburban Portland and, and (3) Spokane in eastern Washington.
Here in Vancouver, the relevant numbers are Portland metro numbers. I can see the downtown Portland skyline from my house and half my neighbors commute to jobs in Portland. Seattle isn’t really relevant. Luckily both OR and WA are pretty closely in sync in terms of social distancing and shelter-in-place mandates.
One thing I think we are going to learn from this experience is how our regional geographies really work. Geographers are going to have decades of research from this crisis. State boundaries are mostly artificial. But also, this is a large and dispersed country. The border between France and Germany, for example, is much more densely populated and connected by roads and railways than the border between OR and WA. And the Pacific Northwest (OR, WA, ID) is really much more physically isolated from the rest of the US than any single country in Europe. Only 1 main highway and rail line running north-south to CA, and two running east-west to the rest of the country. That’s it.
West of the Rockies
@Martin:
History books will not be kind to Trump. He and the pilot fish hovering over his sphincter for treats will be revealed to be incompetent, morbidly stupid, amoral figures. His choices put us where we are today.
Martin
One of my irritations about much of American decision making is that it’s not really decision making. So much of it is simply pandering until a decision is forced upon you. Lots of ‘we’re studying it’. I told my leadership to consider the most severe response they could envision themselves doing – they come in and a whole dorm is infected or someone dies in class from this or whatever – and to do it that day rather than waiting because if they wait, they were weeks too late. They didn’t quite do that, but many of our campuses closed with no cases on campus. My county had 3 cases when we closed, none affiliated with the campus. So, part of that message got through.
So much of our pandemic response are now just taken directly from our earthquake response which is based on the assumption of an earthquake that makes our buildings unsafe, sends everyone home and we work remotely, with some reduction of staff due to forced relocation, injury, etc. Basically the same scenario. But an earthquake is effectively an instantaneous event. You can’t get in front of it, but generally the worst is over in a few seconds (provided you don’t get a tsunami 15 minutes later.) But a pandemic happens in the past. It’s as if 3 weeks ago there was an earthquake but you only now feel it, but the earthquake also lasts weeks instead of seconds. As soon as we saw what a few cases in China forced China into, we should have had the same response here. We didn’t because shutting down the country over a few cases was unthinkable. We needed to consider hundreds of thousands of cases and thousands of fatalities and growing and if we could see shutting down the country then. And if we could do that, then we needed to do it when there were a few cases. You’re going to make the decision. You’re going to be forced to. Have the courage to do it before you are forced to.
Note that Trump still doesn’t believe the situation is dire. Consider what that means.
trollhattan
@West of the Rockies:
How do we get folks to stop considering “Liberal Fascism” and “Clinton Cash” and “The Party of Death” to be history books?
Kent
I’ve been in government and the danger of getting out too far over your skis is always a greater danger to careers than not acting fast enough. We have built up governing systems with so many veto points and so many checks for “study and analysis” that crisis management becomes that much more difficult. No one ever gets reprimanded for following procedure. Many people in authority also confuse “procedure” with the actual law. Every large institution, whether in government, education, or business, has thousands of various “procedures” that are detailed in memos and documents that were approved by various committees and so forth. But they are just that, “procedures” they are not laws handed down by state and federal legislatures. They have no legal authority. They are to GUIDE decision-making, not substitute for it.
The most perfect example was the Federal and State authorities squelching the early testing efforts at the UW in Seattle. They had thousands of samples from flu testing and a valid test to use and were ordered to cease and desist. Utterly inconceivable from the perspective of today. How many lives were lost due to that single decision? Yet no one in the chain of command was empowered to say “we are in a crisis and rules need to be bent”
Martin
Regarding the fragility of this kind of field modeling, my NYC model says that everyone in NYC is already infected. That’s not possible, but the fatality trend does suggest a LOT of people are infected. I know NYC is doing a lot of testing, but the test doesn’t detect the moment you catch it. You have to develop symptoms, so even with perfect testing data, it’s a good week old. Given how testing is happening now, it’s about 13 days old. We’re also still getting data on asymptomatic carriers, and it looks like there could be a lot of them out there that likely would never get tested.
I fear NY is already committed to a terrible negative feedback loop. They didn’t lock down as early as they needed (definitely before their first fatality, and possibly as early as their first reported case) and now their healthcare system will be overrun. Their ability to get this under control may no longer be in their control as that will eventually take down the healthcare workers, and other key bits of infrastructure – morgues, food service, and so on. I think NY needs significant outside help, which can really only come from the feds since NYs neighbors aren’t in great shape themselves. They need resources from currently low-impact states, and those states need to shut down, and that needs to happen now.
The only bit of good news I know of is the report that the doubling of hospitalizations is slowing. I don’t know why that might be, but it runs counter to what’s happening with their fatality data. Cuomo said it was doubling every 4 days, while their fatalities are increasing 10x every 4-5 days. I don’t yet know how to square that. Doubling every 4 days is still unsustainable even for a short period of time, but it’s better than 10x.
Matt McIrvin
I just saw a news story today about health-care workers in the US insisting that they’re seeing far more Covid-19 deaths than official numbers seem to report, everywhere, maybe because dead people aren’t being autopsied. And I’m wondering if this is true or if they’re just mis-extrapolating from what they see around them.
Kent
It is 100% true.
My wife’s organization (Kaiser Permanente) has shifted to virtual care for all but the most critical cases. Their doctors spend all day on the phones and video with patents who present minor or moderate COVID symptoms. They tell them to all self-quarantine and NOT come into the hospital to get tested. Just assume you have it and act accordingly.
They are also seeing increases in deaths due to respiratory failure, both in the hospitals and elderly patients at home who were never tested.
They don’t have the time or equipment to test, so they don’t. They aren’t going to waste the personnel and protective gear to run testing on ambulatory populations.
West of the Rockies
@trollhattan:
I commented last night that between 27-43% of Americans (people everywhere?) are irretrievably ignorant, greedy, and without empathy. To kinda quote GWB, “We have to ask ourselves, is our idiots able to be educationalized?”
Fleeting Ex-istence
Do you think that the Kinsa fever-tracking data is reliable? Are their sample sizes large enough?
Bill Arnold
The rise in my county[1] of confirmed cases has looked fairly linear for the last week. There was a knee where the amount of testing being done jumped by 1-2 orders of magnitude. We’ve been locked down since March 20 and partially locked down the week before that. I am slightly encouraged. (County is 372K). Assuming a 10x infected to confirmed infected ratio, that would put it at about 2% infected. Also, mask wearing has increased to about 20 percent. I leave a mask dangling from my car mirror and wear it when outside the car in town, to encourage others to take this seriously. (The cabin air filter is the in-car alternative.)
[1] Orange County, New York – https://www.orangecountygov.com/1936/Coronavirus
StringOnAStick
@trollhattan: I buy up books like that at library sales, then take them permanently out of circulation. It’s small, but it is something. I saw hardly any of those or Limbaugh’s and the rest books at the last sale.
West of the Rockies
@West of the Rockies:
Of course, if they are, indeed, irretrievably stupid, the answer is no. Stupid is not going away.
Martin
@Matt McIrvin: Yeah, that didn’t age great. But relatively speaking it still holds. Two reasons:
Martin
@Fleeting Ex-istence: I do think it’s generally reliable. I don’t know about the sample size. If they’ve sold millions, then yeah, they’re solid.
You have to consider the possibility that a specific region like Florida might have a flu outbreak at the same time. It’s unlikely, but its far from impossible. Better to act that it’s accurate and apologize for slightly overreacting.
West of the Rockies
I wish this post hadn’t been Big Footed for a more lightweight snark thread.
lee
Things to keep in mind about healthcare workers saying the dead are being under counted.
If 4 workers see the same dead person and one (or more) misremembers the location/details, then that one becomes two or three.
There is a word/phrase for this. Fundamentally the problem is eye witness reporting is notoriously unreliable.
Martin
I want people to think realistically about a vaccine.
There’s two major bottlenecks:
There are other manufacturing methods being looked at, but they too will need equipment manufactured and facilities set up for this kind of scale. The feds should be getting this prepared now. Not sure that they are.
Cam-WA
@What Have the Romans Ever Done for Us?:
Yeah, we were the first on the curve, but our governor diddled around too long before imposing restrictions. Then the first set of restrictions (closing schools) came down, followed later by closing restaurants, etc. and banning gatherings of more than 250, which went to 100, and then to 10. Even when he (finally!) gave his “stay home” restrictions (just last Monday, 3/26!), the tone of his televised speech came across to me as “This is really, really serious…pretty please do as I say and stay home.”
Most businesses are supposed to be closed, by yesterday on the way home from the grocery store I saw a Lowes parking lot that was packed.
Now, full disclosure, I am in Pierce County (think Tacoma), which is definitely not as blue as Seattle and King County. We are very purple, but get there by mixing as blue as possible with wing-nut red as possible.
Anyway, our compliance rate to date isn’t enough to bend the curve very much.
Martin
@lee: Also, we tend to extrapolate this information. If one hospital is undercounting, we assume all are. Well, no. Not all hospitals are equally overrun. If we have an undercount of 5 in 1 of 1000 hospitals, that doesn’t mean we’ve undercounted by 5000, it could just mean an undercount of 5.
Understanding why this is happening helps us to look at the data to figure out how widespread it might be.
Martin
@Cam-WA: Well, we don’t know that. We don’t really know how effective each of these efforts is. The Bay Area ‘work from home’ suggestion seems to have helped more than I would have guessed. Closing schools and bars will help. Lockdowns are the ‘we know this gets everyone to R<sub>0</sub> < 1’ without the iterative process of doing a little, waiting 2 weeks, doing a little more, etc.
Matt McIrvin
@Martin: I’ve been assuming we will take two years to get to mass vaccination. By that point, the first outbreak at least will be over in most of the world, one way or another.
Matt McIrvin
@Martin: I would guess that undercounting would be worse in places where the outbreak is worse. So it may be having the effect of underestimating the pace of growth and the difference between more and less severely affected areas.
joel hanes
@Martin:
The Bay Area has several very major employers whose employees were already accustomed to working from home, and which have rational and performatively community-minded management. So the “work from home” suggestion here was unusually effective, because Apple and Google etc. told tens of thousands of people to start staying home the very next day.
That’s not a thing that can be replicated in many other metropolitan areas.
Flea, RN
Hey Martin – have you seen this?
https://talkingpointsmemo.com/edblog/this-is-very-important-from-italy-please-read
I know that many people are dying without an autopsy, or confirmation of COVID positive status; how are you using this info in your models?
joel hanes
@Matt McIrvin:
There’s some hope that serum therapy will work — I think there’d a trial of this underway. (Extract antibody-rich blood serum from recovered patients, give it or an extract to those in the early stages of the disease.) If it’s effective, it may allow hospitals to drive down the fraction of cases that become serious or critical. An advantage of the serum approach, I think, is that hospitals may already have most of the equipment needed to do the lab work (I am not an expert).
Martin
@Flea, RN: Yeah, that was part of my update in #7.
Fair Economist
What worries me about numbers in places like Cali and Italy is that fairly strong distancing measures were in place before shelter in place/lockdown. Especially in Italy, I’d have expected more of an effect already. Lombardy is several days past 2 weeks from lockdown.
Fair Economist
@Martin: In terms of everybody in NYC being infected, the tests there are coming out 16% positive and that’s going to be a group selected for higher probability of infections. So I don’t see the actual rate being even that high. Maybe 5% if I had to guesstimate.
Martin
@Fair Economist: New confirmed cases in Italy are going down and have been for a few days. So, that’s working. In CA we need to wait a few more days, and even then the complete lack of community testing may not reveal much. We’ll probably get some anecdotal information from hospitals that they’re getting fewer new cases, etc.
The piecemeal effort in the US will make it a lot harder to find the clear inflection points like China showed and Italy will likely show. But there’s no reason to believe that our lockdowns won’t halt the growth on the 13/21(ish) day timelines. How rapidly they drop, that’s a whole other matter.
Fair Economist
@Martin: Unfortunately cases in Italy *increased* today and yesterday. Still below the peak, but looking more flat than anything else. China saw drops set in faster.
Martin
@Fair Economist: Depends on the rate of spread. If we’re not testing people until an average of 13 days after infection (in part due to the nature of the test) and it can be transmitted as early as day 2, with a high enough R0, even with perfect testing you could be undercounting by a factor of 10.
Put another way, before things like lockdowns and herd immunity kick in, for every person who tests positive, there are around 10x as many people who are infected but won’t show positive when tested because their symptoms haven’t kicked in yet. And that ignores however many people are infectious and asymptomatic throughout the disease which might be 2x more.
Martin
@Fair Economist: Yeah, I suspect that’s going to be a factor of two things:
Kent
I’m assuming that other countries will be quicker to rush vaccines to the market than the US might due our more cumbersome systems. So China might be mass-deploying vaccines while the US is still in the testing phase. But maybe that isn’t as likely as I assume. But based on everything else we have done, I wouldn’t be surprised if the US is one of the LAST developed countries to roll out vaccines.
Feathers
@Martin: I think hurricane response is the primary model in the US rather than earthquake, but that may be my east coast bias. Something that you know is coming, but has a predictable pattern.
All your points about people refusing to step outside the rules and procedures when necessary. Very, very true. I’ve been reading that one of the real issues is getting masks to hospitals. The masks have to meet FDA standards. There is equipment available that meet the standards of their home country, but not the FDA. Unacceptable. Therefore US medical staff are using garbage bags and masks made by home sewists.
Ruckus
@Martin:
trump doesn’t consider he is dire either.
Don’t have to consider, it’s way too late for that, we can see it clearly.
ziggy
What I’m seeing in Washington is completely different than others imply. The numbers are not going up very quickly, certainly not exponentially like in many areas.. About 200 additional per day in King County. In my county, Thurston, we’ve only gone up from 11 to 14 cases in the last couple days. And there is a LOT more testing going on now, several drive-through testing sites have opened up around the state. But testing criteria have become more stringent. Maybe things will change over the next few days as results are just starting to pour in.
http://depts.washington.edu/labmed/covid19/
https://www.kingcounty.gov/depts/health/communicable-diseases/disease-control/novel-coronavirus/data-dashboard.aspx
(download pdf from last site)
Most of the deaths are in nursing homes, 37 (out of total of 109) from the Life Care Center alone!. And because we started much earlier, many of these cases have already resolved. Our state was late in statewide “lockdown”, but the very first in the nation to institute any “social distancing” and work-from-home directives. I just get the impression that things are not quite as dire as other areas of the nation, but like to hear other opinions, of course.
There’s a chart I saw that compares the states, very informative, still looking for it…..
What Have the Romans Ever Done for Us?
@Cam-WA: Yikes. Here in the DC area we shut down mostly about 2 weeks ago. I haven’t been into the office since the 13th. I think the restaurants and bars shut down around then (last time I went out to eat was the 13th).
Ruckus
@Martin:
Wanna bet that some trump believer is going to do/is doing everything to delay any concept of this?
Another Scott
@Cam-WA: Home improvement warehouses like Lowes are exempt from closing in VA. The full list is here (4 page .pdf).
It would be great if everyone could stay home for 2-3 weeks, recovery from this pandemic would be much faster, but reality intrudes. :-(
Cheers,
Scott.
ziggy
I think that was also a big factor in the Seattle area, with a very high proportion of tech workers. When the work-from-home edict was put out, the streets emptied the very next day. An area that is much more blue collar probably won’t be as successful at cutting social interactions.
ziggy
@Another Scott: That is a whole different can of worms. I’ve been poring over the “essential workers” lists, trying to figure out if I can work or not (landscaper in WA state). The number and types of exceptions is mind-boggling–pot stores, nurseries and greenhouses, any store that sells any type of food, construction workers, any type of home repair business, hardware stores,etc…–and of course it is completely self-monitored, no-one has time to supervise this.
Martin
@Kent: US is quite good overall. We tend to be slow on the trials because we have higher standards to minimize risk to trial participants, but in terms of labs to develop the vaccine and even to produce it, we’re among the best in the world.
But we’re looking to produce 7 billion doses of a vaccine in as short a period of time as possible. That’s never been done before. And the US can definitely do it provided that the people who need to initiate the effort aren’t asleep at the wheel.
I bet anything that Gavin lines up those contracts before the feds or anyone else does and doesn’t risk waiting for the feds.
Martin
@Feathers: Here in CA we have pretty solid earthquake plans. One benefit earthquakes have over hurricanes is the 2nd guessing of risk. It’s hard to tell how early to pull the trigger on a plan relative to a hurricane forecast. For an earthquake, it’s all after the fact, so you know definitively when to start reading from the binder.
Martin
@ziggy: Our landscapers are working, but no longer as a team. One person, no interaction with others. I’m fine with that – almost no risk.
Another Scott
@Martin: Except they share the truck, and load and unload the equipment together, interact with customers and foremen, etc., etc.
:-(
I understand it, but it’s still not anywhere as good as people actually staying home.
[eta:] At least that’s what I see here in NoVA – teams of 2-4 guys working as always. Similarly with home cleaning services – 2 people as always. (sigh)
Cheers,
Scott.
PJ
@Martin: New York residents have been instructed not to go to a hospital if they suspect or know they have coronavirus unless they are having serious respiratory problems. I assume this means that a lot of people who in other circumstances might be hospitalized are riding it out (or dying) at home.
Martin
@Another Scott: No, I’m just seeing one guy in a truck. Does everything by himself.
Miki
I’m happy as a pig in shit that I live in Frostbite Falls and we have a Gov who has a brain and is looking to science to inform his decisions. He ordered lock down light a couple of weeks ago and it’s helped but the FUCKING LACK OF TESTING means we couldn’t flatten the curve. The next 2 weeks we’re on stay at home to give the infrastructure time to scale up to try to meet the inevitable surge in infections and hospitalizations. Will it work? Will it help? I fucking hope so.
I get my care solely from the VA until July when I turn 65 and can add Medicare to the mix.. I have no confidence it can handle this shit show but I know it will try.
So I stay home, unapologetically for once.
Momus
I’ve been following the Illinois data. I get a similar exponent e^0.29, Rsq = 0.97 over the past 25 days, 2500 cases, 25 deaths. Since retired from an R&D dept 15 years ago I will opine that Excel has been redesigned for clerks making tables rather than for exploratory data analysis. Both the Illinois Department of Public Health and my county department are supplying information, daily. I’d been thinking about the under reporting issues. Will see if I can come up with it over the weekend.